1常见的垃圾回收器
1.1 引用计数收集器
引用计数是垃圾收集器中的早期策略。在这种方法中,堆中每个对象(不是引用)都有一个引用计数。当一个对象被创建时,且将该对象分配给一个变量,该变量计数设置为1。当任何其它变量被赋值为这个对象的引用时,计数加1(a = b,则b引用的对象+1),但当一个对象的某个引用超过了生命周期或者被设置为一个新值时,对象的引用计数减1。任何引用计数为0的对象可以被当作垃圾收集。当一个对象被垃圾收集时,它引用的任何对象计数减1。
优点:引用计数收集器可以很快的执行,交织在程序运行中。对程序不被长时间打断的实时环境比较有利。
缺点: 无法检测出循环引用。如父对象有一个对子对象的引用,子对象反过来引用父对象。这样,他们的引用计数永远不可能为0.
1.1 跟踪收集器
早期的JVM使用引用计数,现在大多数JVM采用对象引用遍历。对象引用遍历从一组对象开始,沿着整个对象图上的每条链接,递归确定可到达(reachable)的对象。如果某对象不能从这些根对象的一个(至少一个)到达,则将它作为垃圾收集。在对象遍历阶段,GC必须记住哪些对象可以到达,以便删除不可到达的对象,这称为标记(marking)对象。
下一步,GC要删除不可到达的对象。删除时,有些GC只是简单的扫描堆栈,删除未标记的未标记的对象,并释放它们的内存以生成新的对象,这叫做清除(sweeping)。这种方法的**问题在于内存会分成好多小段,而它们不足以用于新的对象,但是组合起来却很大。因此,许多GC可以重新组织内存中的对象,并进行压缩(compact),形成可利用的空间。2:一些具体的常用的垃圾搜集算法
(1)标记-清除
这种收集器首先遍历对象图并标记可到达的对象,然后扫描堆栈以寻找未标记对象并释放它们的内存。这种收集器一般使用单线程工作并停止其他操作。并且,由于它只是清除了那些未标记的对象,而并没有对标记对象进行压缩,导致会产生大量内存碎片,从而浪费内存。
(2)标记-压缩
有时也叫标记-清除-压缩收集器,与标记-清除收集器有相同的标记阶段。在第二阶段,则把标记对象复制到堆栈的新域中以便压缩堆栈。这种收集器也停止其他操作。
(3)复制
这种收集器将堆栈分为两个域,常称为半空间。每次仅使用一半的空间,JVM生成的新对象则放在另一半空间中。GC运行时,它把可到达对象复制到另一半空间,从而压缩了堆栈。这种方法适用于短生存期的对象,持续复制长生存期的对象则导致效率降低。并且对于指定大小堆来说,需要两倍大小的内存,因为任何时候都只使用其中的一半。
(4) 增量收集器
增量收集器把堆栈分为多个域,每次仅从一个域收集垃圾,也可理解为把堆栈分成一小块一小块,每次仅对某一个块进行垃圾收集。这会造成较小的应用程序中断时间,使得用户一般不能觉察到垃圾收集器正在工作。
(5)分代
复制收集器的缺点是:每次收集时,所有的标记对象都要被拷贝,从而导致一些生命周期很长的对象被来回拷贝多次,消耗大量的时间。而分代收集器则可解决这个问题,分代收集器把堆栈分为两个或多个域,用以存放不同寿命的对象。JVM生成的新对象一般放在其中的某个域中。过一段时间,继续存在的对象(非短命对象)将获得使用期并转入更长寿命的域中。分代收集器对不同的域使用不同的算法以优化性能。
3 新生代 老生代 算法
在java内存中:JVM内存结构由堆、栈、本地方法栈、方法区等部分组成,另外JVM分别对新生代和旧生代采用不同的垃圾回收机制。
1)堆
所有通过new创建的对象的内存都在堆中分配,其大小可以通过-Xmx和-Xms来控制。堆被划分为新生代和旧生代,新生代又被进一步划分为Eden和Survivor区,最后Survivor由FromSpace和ToSpace组成,结构图如下所示: 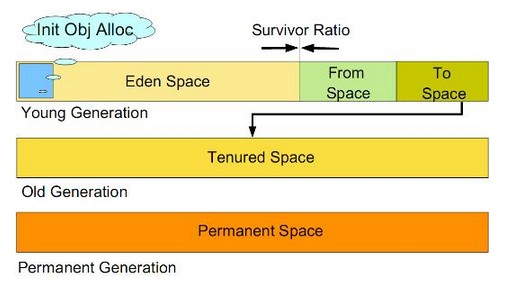 新生代。新建的对象都是用新生代分配内存,Eden空间不足的时候,会把存活的对象转移到Survivor中
新生代。新建的对象都是用新生代分配内存,Eden空间不足的时候,会把存活的对象转移到Survivor中
2)方法区
存放了要加载的类信息、静态变量、final类型的常量、属性和方法信息。JVM用持久代(PermanetGeneration)来存放方法区
4 JVM垃圾回收机制
JVM分别对新生代和旧生代采用不同的垃圾回收机制 新生代的GC:
新生代通常存活时间较短,因此基于Copying算法来进行回收,所谓Copying算法就是扫描出存活的对象,并复制到一块新的完全未使用的空间中,对应于新生代,就是在Eden和FromSpace或ToSpace之间copy。 旧生代的GC:
旧生代与新生代不同,对象存活的时间比较长,比较稳定,因此采用标记(Mark)算法来进行回收,所谓标记就是扫描出存活的对象,然后再进行回收未被标记的对象,回收后对用空出的空间要么进行合并,要么标记出来便于下次进行分配,总之就是要减少内存碎片带来的效率损耗。在执行机制上JVM提供了串行GC(SerialMSC)、并行GC(parallelMSC)和并发GC(CMS),具体算法细节还有待进一步深入研究。
HotSpot的算法实现
1 枚举根节点,可达性分析 需要GC停顿,避免此时建立的新的引用。 系统不需要一个不漏的检查完说有上下文和全局的引用位置。 虚拟机是有办法直接得知哪些地方存放着对象的引用,通过oopmap的数据结构来达到的。
2 安全点 oopmap可能导致引用关系发生变化,,hotspot没有为每条指令都生产oopmap 只是在特定位置记录,这些位置称为安全点。即程序执行时不是在所有地方都能停顿下来开始gc。只有到达安全点 才可以
分代收集的内存分配
对象的内存分配,往大方向上讲就是在堆上分配,对象主要分配在新生代的 Eden Space和From Space,少数情况下会直接分配在老年代。如果新生代的Eden Space和From Space的空间不足,则会发起一次GC,如果进行了GC之后,Eden Space和From Space能够容纳该对象就放在Eden Space和From Space。在GC的过程中,会将Eden Space和From Space中的存活对象移动到To Space,然后将Eden Space和From Space进行清理。如果在清理的过程中,To Space无法足够来存储某个对象,就会将该对象移动到老年代中。在进行了GC之后,使用的便是Eden space和To Space了,下次GC时会将存活对象复制到From Space,如此反复循环。当对象在Survivor区躲过一次GC的话,其对象年龄便会加1,默认情况下,如果对象年龄达到15岁,就会移动到老年代中。